Unternehmen und Lieferanten sind permanent auf der Suche nach Möglichkeiten, noch schneller, noch effizienter, noch kostengünstiger zu produzieren. Maschinelle Übersetzungsprogramme (MÜ-Programme), die in früheren Jahren fast ausschließlich regelbasiert waren, haben lange ein Schattendasein gefristet. Erst mit der Verbreitung statistischer Verfahren nahm die Qualität maschinell erstellter Übersetzungen deutlich zu und brachte MÜ als Produktionsalternative auf den Plan.
Maschinelle Übersetzung als selbstständiges Produktionsverfahren wenig verbreitet
Bis heute ist MÜ als selbstständiges Produktionsverfahren für die Übersetzung technischer Dokumentation noch verhältnismäßig wenig verbreitet. Es wird entweder zu Informationszwecken für den internen Gebrauch oder in Verbindung mit Post-Editing für die Veröffentlichung gewisser Informationen (z. B. im Bereich technischer Support oder bei stark standardisierten Informationen) verwendet.
Trend zur Integration von MÜ in Translation-Memory-Systeme
Relativ neu ist aber die Integration von MÜ in Translation-Memory-Systeme. Maschinelles Übersetzen ist dadurch kein separater Prozess mehr, sondern erfolgt zeitgleich mit der Humanübersetzung im Übersetzungseditor.
Sobald das Translation-Memory keinen passenden Vorschlag für eine Übersetzung findet, springt das integrierte maschinelle Übersetzungssystem ein und unterbreitet dem Übersetzer einen Vorschlag. Diesen Vorschlag kann der Übersetzer übernehmen oder ändern und anschließend bestätigen.
Die meisten Anbieter von TM-Systemen bieten Integration von MÜ-Modulen an
Inzwischen bieten fast alle bekannten Translation-Memory-Systeme die Integration von Modulen für maschinelles Übersetzen an. Das fängt bei führenden Technologien wie SDL Trados Studio an und endet bei kostenlosen Programmen wie Wordfast Anywhere. Die integrierten maschinellen Übersetzungsmodule sind teils eigene Entwicklungen (Beispiel SDL Language Cloud), teils öffentliche Technologien wie Google Translate.
Keine klare Trennung zwischen humanem und maschinellem Übersetzen
Die frühere klare Trennung zwischen humanem und maschinellem Übersetzen ist nun nicht mehr vorhanden. Zwar sind maschinell vorgeschlagene Segmente in der Regel mit einem entsprechenden Attribut versehen, aber sie werden aufgrund des enormen Zeitdrucks oft nicht gleich vom Übersetzer oder Lektor als solche erkannt und behandelt.
Negative Auswirkungen auf Qualität der Übersetzungen und Translation-Memorys
Dieser schleichenden Verbreitung von maschinell übersetzten oder angepassten Segmenten in Übersetzungen wurde bisher noch wenig Beachtung geschenkt, obwohl sie auf mittlere Sicht Folgen für die Qualität der Übersetzungen und Translation-Memorys hat.
Vertraulichkeit der Daten bei MÜ nicht gewährleistet
Es ist also an der Zeit, Strategien für den Umgang mit maschinell übersetzten Segmenten zu entwickeln. Zuerst einmal geht es um die Vertraulichkeit der Daten. Kein Unternehmen kann ein Interesse daran haben, dass vertrauliche Informationen einfach an öffentliche Maschinen wie Google geschickt werden. Dies sollte auf jeden Fall im Vertrag zwischen Übersetzer und Auftraggeber geregelt sein.
Die Maschine macht andere Übersetzungsfehler als ein Mensch
Der nächste Punkt betrifft die Art von Fehlern, die ein maschinelles Übersetzungsprogramm macht. Auch Maschinen machen Fehler, aber sie unterscheiden sich von den Fehlern, die ein Übersetzer macht. Die maschinellen Fehler betreffen folgende Aspekte:
(1) Stil: Die meisten angewandten MÜ-Programme sind schwerpunktmäßig statistisch basiert, auch wenn sie einige Regeln verwenden, um die Ergebnisse aus der Statistik zu optimieren. Das führt dazu, dass der Satzbau sich sehr stark am Original anlehnt. Die Übersetzungen sind nicht immer falsch, klingen aber sehr wörtlich. Beispiel:
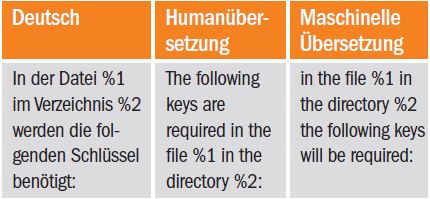
(2) Kontexterkennung: Sprachen sind nicht exakt und lassen noch viel Raum für Interpretationen. Besonders bei Verben und Wörtern der Alltagssprache spielt der Zusammenhang eine große Rolle. Der Mensch erkennt diesen Zusammenhang mühelos, aber MÜ-Programme haben immer wieder ihre Schwierigkeiten damit:

(3) Vollständigkeit und Grammatik: Bei statistischen Verfahren zerlegen MÜ-Programme Sätze in Wortgruppen. Für jede Wortgruppe sucht das Programm den besten Match in seiner indizierten zweisprachigen Datenbank. Es kommt durchaus vor, dass der statistisch bessere Match zusätzliche Wörter enthält bzw. dass Wörter fehlen und unter Umständen auch grammatikalisch mit den anderen gefundenen Wortgruppen nicht übereinstimmen. Dies aufzuspüren ist besonders schwer, weil die fehlenden bzw. zusätzlichen Wörter nicht sofort auffallen. Beispiel:
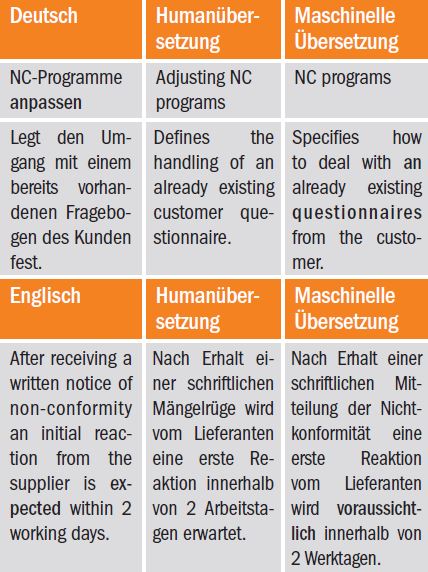
(4) Terminologie: Man könnte zwar davon ausgehen, dass Programme bei der Verwendung einer vorgegebenen Fachterminologie besser abschneiden als ein Mensch, aber leider ist auch das nicht immer der Fall. Da statistische Verfahren die Häufigkeit der Verwendung einer bestimmten Übersetzung in den Vordergrund stellen, kann es durchaus passieren, dass in der Übersetzung ein anderer Fachbegriff vorkommt.
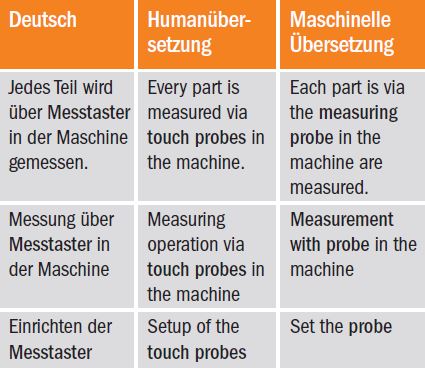
Qualitätssicherungstools können MÜ-Fehler nur eingeschränkt erkennen
Wie einfach ist es, diese Fehler aufzuspüren? Qualitätssicherungstools können sie nur eingeschränkt erkennen. Solche Programme haben sich auf formelle Vergleiche (z. B. Vergleich der Zahlen oder bestimmter Fachbegriffe in der Ausgangs- und Zielsprache) spezialisiert. Wir haben es bei MÜ mit einer andersartigen „Fehlergüte“ zu tun.
Arbeit vom Übersetzer auf den Lektor verlagert
Da viele MÜ-Fehler aber nur durch genaues Durchlesen der Texte in beiden Sprachen zu erkennen sind, hat man im Grunde keine Arbeit gespart, sondern die Arbeit vom Übersetzer auf den Lektor verlagert. Dazu kommt noch eine größere Gefahr, da MÜ-Fehler oft Sinnfehler sind. Das klingt nach einem Eigentor.
Schleichender Prozess der „Entmenschlichung“ des Übersetzens
Diese Entwicklung könnte man als schleichenden Prozess der „Entmenschlichung“ des Übersetzens bezeichnen. Das bedeutet, dass der Anteil an maschinell erzeugten Übersetzungen in Translation-Memorys tendenziell zunehmen wird.
Maschinell übersetzte Segmente sollten gekennzeichnet werden
Es ist daher wichtig, dass Auftraggeber und Übersetzer sich darüber Gedanken machen, mit welchen Attributen diese Segmente in TMs und in Projekten gekennzeichnet werden und wie man sie effizient lektorieren kann.
Hier sind Firmen und Dienstleister im Vorteil, die von Anfang an den möglichen Einsatz von Mischverfahren mit MÜ-Komponente planen, etwa durch für MÜ optimierte Ausgangstexte oder durch gezielte Prüfverfahren für maschinell übersetze Segmente.
[Text: D.O.G. Dokumentation ohne Grenzen GmbH. Absatzgliederung, Haupt- und Zwischenüberschriften sowie Bildunterschriften von Richard Schneider. Quelle: D.O.G.news 03/2016. Wiedergabe mit freundlicher Genehmigung von Dr. François Massion. Bild: D.O.G.]