
Sprachwissenschaftler der Universität Passau und des Max-Planck-Instituts für evolutionäre Anthropologie (MPI-EVA) in Leipzig haben das Vokabular zur Bezeichnung von Körperteilen in 1.028 Sprachen verglichen. Die Studie gibt Einblicke in universelle und kulturelle Faktoren der Ausprägung des jeweiligen Wortschatzes.
Prof. Dr. Johann-Mattis List, der an der Universität Passau den Lehrstuhl für Multilinguale Computerlinguistik innehat, entwickelt gemeinsam mit Kollegen Algorithmen, um die Frage zu untersuchen, wie der Wortschatz in verschiedenen Sprachen gebildet wird. Er kooperiert dazu mit der Abteilung für Sprach- und Kulturevolution am MPI für evolutionäre Anthropologie in Leipzig.
Die Studie mit dem Titel „Universal and cultural factors shape body part vocabularies“ ist im renommierten Nature-Journal Scientific Reports erschienen.
Körper überall auf der Welt gleich, aber sprachliche Einteilung unterscheidet sich
„Obwohl unsere Körper ähnlich aufgebaut sind, unterscheiden sich die Sprachen darin, wie sie den Körper unterteilen und diese Teile benennen“, sagt Annika Tjuka, ehemalige Doktorandin bei Prof. Dr. List und jetzt Postdoc am MPI-EVA, die die Studie initiiert und durchgeführt hat. Sie sagt:
Im Englischen haben wir ein Wort für Arm und ein anderes für Hand, aber Wolof, eine Sprache, die im Senegal in Westafrika gesprochen wird, verwendet ein Wort, loxo, um beide Körperteile zu bezeichnen.
Alle Sprecher haben eines gemeinsam: einen menschlichen Körper. Warum also unterscheiden sie sich darin, welchen Teilen sie eindeutige Namen geben?
Das Deutsche unterscheidet sprachlich zwischen Fuß und Bein, während andere Sprachen die gesamte Extremität als einen einzigen Körperteil begreifen und entsprechend nur mit einem einzigen Wort benennen.
Ein bekanntes Beispiel aus dem Französischunterricht mag in diesem Zusammenhang der Verdeutlichung dienen: Das Deutsche kennt nur eine Bezeichnung für die langen Hornfäden, die aus der Haut wachsen, nämlich die Haare. Im Französischen hingegen nimmt man es genauer und unterscheidet zwischen Kopfbehaarung (les cheveux) und Körperbehaarung (les poils).
Solche und andere Unterschiede im Vokabular für Körperteile in verschiedenen Sprachen beschäftigen die Sprachwissenschaft, Anthropologie und Psychologie seit Jahren. Ähnlich wie bei den Grundsätzen, die für den semantischen Bereich der Farbe entwickelt wurden, können allgemein gültige Regeln identifiziert und kulturspezifische Variationen gegenübergestellt werden.
Computergestützte Verarbeitung großer Datenmengen
Das Aufkommen neuer computergesteuerter Methoden in der Netzwerkanalyse ermöglicht nun groß angelegte Vergleiche des Wortschatzes in bestimmten semantischen Domänen, um allgemein gültige und kulturelle Strukturen zu untersuchen.
Sprache mit Hand hat meist auch Fuß
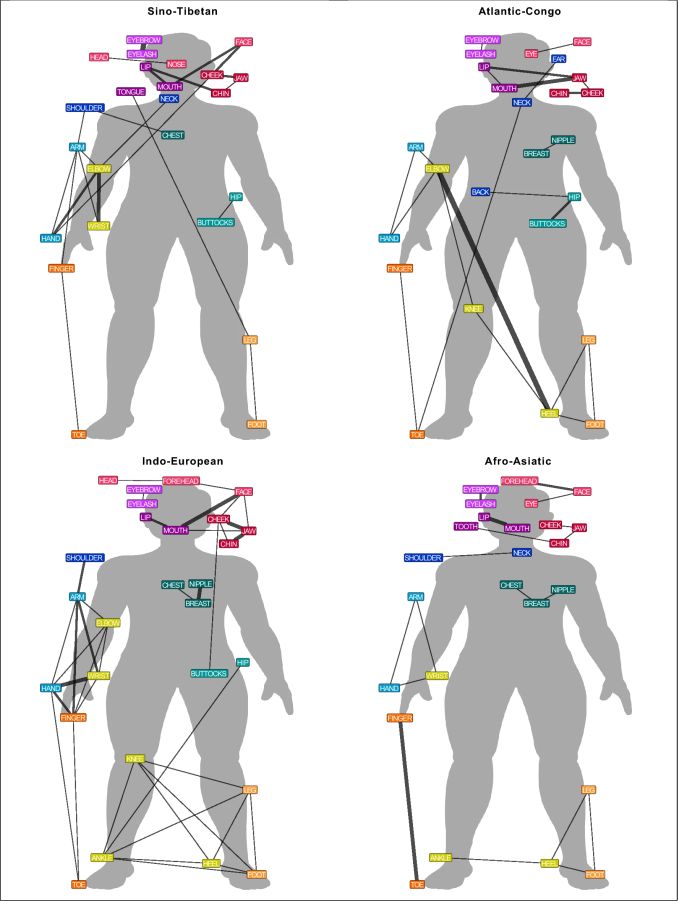
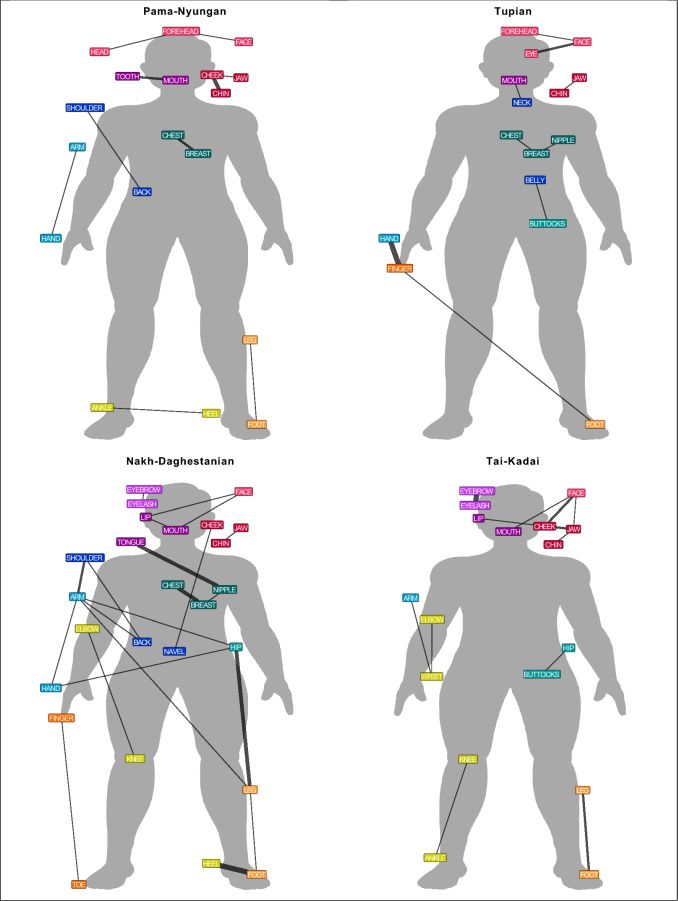
Die Studie bestätigt eine der Regeln, wonach es ein eigenes Wort für Fuß gibt, wenn auch eines für Hand existiert. Aber die Ergebnisse zeigen auch, dass ein Körperteil, der mit einem anderen verbunden ist, mit größerer Wahrscheinlichkeit ein und denselben Namen trägt.
Ein Grund für dieses Muster ist, dass sich Sprachen wie Wolof auf die Funktionen konzentrieren, die zwei Teile miteinander verbinden. Die Sprecher wissen, dass wir einen Ball mit unserer Hand und unserem Arm werfen oder dass wir mit unserem Bein und unserem Fuß gehen.
Sprachen wie das Englische und das Deutsche hingegen konzentrieren sich auf visuelle Hinweise wie das Handgelenk oder den Knöchel, um Teile voneinander zu trennen.
Das Vokabular für Körperteile variiert von Sprache zu Sprache. Innerhalb dieser Vielfalt zeichnen sich jedoch allgemeine Tendenzen ab. Dr. Tjuka plädiert für weitere Forschungen auf diesem Gebiet:
Um die Faktoren zu verstehen, die die sprachliche Vielfalt prägen, brauchen wir mehr Daten. Wir müssen die Sprachen dokumentieren, die in Gebieten mit einer hohen Sprachenvielfalt gesprochen werden. Und wir müssen Daten über den soziologischen Kontext sammeln, in dem diese Sprachen gesprochen werden.
Nutzung der Lexibank
Für die aktuelle Studie wird eine bestehende Datenbank, Lexibank (https://lexibank.clld.org), genutzt, die am MPI-EVA in Leizpig und am Passauer Lehrstuhl für Multilinguale Computerlinguistik fortentwickelt wird. Dabei handelt es sich um eine große Sammlung von Wortlisten für mehr als tausend Sprachen.
Mit einem rechnergestützten Ansatz wurden Wörter für 36 Körperteile in all diesen Sprachen extrahiert. Anschließend wurden die Beziehungen zwischen den Wörtern einer Netzwerkanalyse unterzogen.
Die Datenbank wird auch genutzt, um zu verstehen, wie sich Wortfamilien in verschiedenen Sprachen bilden.
Prof. Dr. List war früher als leitender Forscher am MPI-EVA in Leipzig tätig, heute leitet er die ERC-geförderte Forschungsgruppe „ProduSemy“ an der Universität Passau. Er erläutert:
Wir haben mehrere Jahre gebraucht, um die Daten in der Lexibank-Sammlung zusammenzutragen. Jetzt können wir beginnen, die Daten auf verschiedene Weise zu analysieren.
Weiterführender Link
- Originalpublikation: https://doi.org/10.1038/s41598-024-61140-0
Universität Passau, red