
Im Gegensatz zu Tech-Konzernen können mittelständische Unternehmen meist nur auf wenige Dialoge mit Kunden zurückgreifen, um damit Chatbots für Kundengespräche zu entwickeln. Ein Forschungsverbund, an dem Wissenschaftler der Universität des Saarlands beteiligt sind, möchte das ändern.
Die Projektpartner möchten ein Sprachdialogsystem entwickeln, das mit wenigen Daten auskommt, am Ende aber genauso gut ist wie ein System eines IT-Konzerns. Gefördert wird „SLIK – Synthese linguistischer Korpusdaten“ vom Bundesforschungsministerium.
Konzerne verfügen über gigantische Datenmengen – Mittelständler nicht
Der technische Fortschritt eilt mir riesigen Schritten voran. Die großen IT-Firmen wie Google, Amazon und Microsoft können mit gigantischen Datenmengen ihre auf künstlicher Intelligenz (KI) basierenden Algorithmen trainieren, zum Beispiel auf dem Gebiet der Sprachtechnologie. Wer die Sprachdialogsysteme dieser Firmen nutzt, etwa in Form von Amazons „Alexa“, der merkt oft fast keinen Unterschied mehr im Vergleich zu einem menschlichen Ansprechpartner.
Das ist schön für die Nutzer dieser Systeme und natürlich für die riesigen Tech-Firmen. Aber was ist mit den unzähligen kleinen und mittelständischen Unternehmen (KMU), die diese riesige Menge an Trainingsdaten nicht zur Verfügung haben?
KMU müssen Know-how oft einkaufen
Ihnen droht, im Wettbewerb mit den Großen die Luft auszugehen. Denn entweder müssen sie teuer das Know-how der großen Anbieter einkaufen oder sie müssen mit großer Mühe und ebenfalls viel Geld Trainingsdaten zusammenbekommen und ein eigenes Sprachdialogsystem entwickeln.
Denn bei der Entwicklung eines KI-basierten Sprachdialogsystems gilt nach wie vor oft das simple Prinzip: Viel hilft viel. Man braucht viele Kundengespräche, um zum Beispiel einen guten Chatbot zu programmieren.
Kleinere Unternehmen müssten also Call Center aufbauen und massenhaft Kundendialoge aufzeichnen, verschriften und damit dann eine KI trainieren. Das ist meist finanziell und organisatorisch nicht machbar.
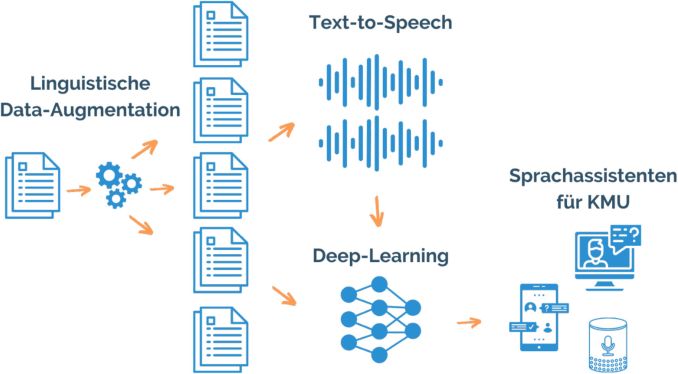
Trotz kleiner Datenbasis gut funktionierende Dialogsoftware entwickeln
Hier möchte nun ein Forschungsprojekt ansetzen, an dem Dietrich Klakow, Professor für Sprach- und Signalverarbeitung an der Universität des Saarlandes, beteiligt ist. Gemeinsam mit den Projektpartnern Kauz GmbH, die das Projekt federführend leitet, und Aristech GmbH, zwei auf Sprachtechnologie spezialisierten Softwareunternehmen, möchte Dietrich Klakow eine Technologie entwickeln, die es ermöglicht, bereits aus sehr wenigen Trainingsdaten eine gut funktionierende Dialogsoftware zu entwickeln.
Dabei gibt es einiges zu beachten. „Solche kleineren Unternehmen haben oft einen sehr engen Kundenkreis“, sagt Dietrich Klakow. Ein Mittelständler aus der Industrie führt also Kundengespräche, die sehr spezielles Vokabular und Inhalte haben. Um eine KI darauf zu trainieren, müsste man viele Dialoge aufzeichnen, was aus den genannten Gründen keine machbare Option ist.
Spracherkennung, Data Augmentation, künstliche Intelligenz
Der Ansatz des Forschungs-Trios aus den beiden Firmen und Dietrich Klakows Lehrstuhl lautet daher, das Beste aus zwei Welten zu vereinen. „Kauz macht klassische Dialogsysteme, Aristech ist stark in der Spracherkennung und wir sind spezialisiert auf sprachtechnologische künstliche Intelligenz“, führt Dietrich Klakow weiter aus. Aus der Not also eine Tugend, aus wenigen Trainingsdaten viele zu machen, das ist das Kunststück, das den Verbundpartnern gelingen soll.
„Data Augmentation“, die künstliche Vervielfältigung von Daten, sowohl auf Basis des sprachlichen Wissens von Kauz und Aristech als auch mit Hilfe von Klakows Lehrstuhl entwickelten Verfahren, soll das Fundament schaffen, um große „Korpora“, also einen großen Fundus an brauchbaren Sprachbausteinen, aufzubauen. Damit kann dann eine Künstliche Intelligenz genauso gut lernen wie eine, die auf „natürlich gewonnenen“ Korpora basiert, die großen Firmen zur Verfügung stehen.
Der Vorteil des klassischen Ansatzes, eine „nicht-lernende“ Software zu entwickeln, ist, dass er sehr individuell auf die Kundenwünsche zugeschnitten ist. Der Wermutstropfen: „Solche Chatsysteme sind nicht perfekt in allen Situationen“, erklärt Dietrich Klakow. „Verknüpfen wir nun diesen klassischen Ansatz mit einem KI-basierten System, könnten wir im Idealfall aus sehr wenigen Trainingsdaten ein neues Dialogsystem bauen, das in vielen Gesprächssituationen, die für einen Mittelständler relevant sind, gut funktionieren kann.“
Ambitionierte Ziele sollen innerhalb von zwei Jahren erreicht werden
Die Vision der Kooperationspartner ist ambitioniert. Am Ende hoffen sie, mit sehr wenigen Beispieldialogen – zehn, zwanzig, dreißig – ein solides Sprachdialogsystem zu entwerfen, sodass Kunden am „anderen Ende“ des Dialogs den Unterschied zu einem System der Tech-Giganten nicht mehr feststellen können.
Ob das gelingt, wird im Frühjahr 2024 feststehen. Bis dahin läuft das Projekt „SLIK – Synthese linguistischer Korpusdaten“, das im Frühjahr 2022 gestartet wurde.
Von den 1,44 Millionen Euro Fördergeld, das vom Bundesforschungsministerium kommt, gehen rund 300.000 Euro an die Universität des Saarlandes.
Friederike Meyer zu Tittingdorf (UdS)